Quantile QT-Opt for Risk-Aware
Vision-Based Robotic Grasping
Abstract
The distributional perspective on reinforcement learning (RL) has given rise to a series of successful Q-learning algorithms, resulting in state-of-the-art performance in arcade game environments. However, it has not yet been analyzed how these findings from a discrete setting translate to complex practical applications characterized by noisy, high dimensional and continuous state-action spaces. In this work, we propose Quantile QT-Opt (Q2-Opt), a distributional variant of the recently introduced distributed Q-learning algorithm for continuous domains, and examine its behaviour in a series of simulated and real vision-based robotic grasping tasks. The absence of an actor in Q2-Opt allows us to directly draw a parallel to the previous discrete experiments in the literature without the additional complexities induced by an actor-critic architecture. We demonstrate that Q2-Opt achieves a superior vision-based object grasping success rate, while also being more sample efficient. The distributional formulation also allows us to experiment with various risk distortion metrics that give us an indication of how robots can concretely manage risk in practice using a Deep RL control policy. As an additional contribution, we perform batch RL experiments in our virtual environment and compare them with the latest findings from discrete settings. Surprisingly, we find that the previous batch RL findings from the literature obtained on arcade game environments do not generalise to our setup.
Introduction
The new distributional perspective on RL has produced a novel class of
Deep Q-learning methods that learn a distribution over the state-action
returns, instead of using the expectation given by the traditional value
function. These methods, which obtained state-of-the-art results in the
arcade game environments
First, their ability to preserve the multi-modality of the action values naturally accounts for learning from a non-stationary policy, most often deployed in a highly stochastic environment. This ultimately results in a more stable training process and improved performance and sample efficiency. Second, they enable the use of risk-sensitive policies that no longer select actions based on the expected value, but take entire distributions into account. These policies can represent a continuum of risk management strategies ranging from risk-averse to risk-seeking by optimizing for a broader class of risk metrics.
Despite the improvements distributional Q-learning algorithms demonstrated in the discrete arcade environments, it is yet to be examined how these findings translate to practical, real-world applications. Intuitively, the advantageous properties of distributional Q-learning approaches should be particularly beneficial in a robotic setting. The value distributions can have a significant qualitative impact in robotic tasks, usually characterized by highly-stochastic and continuous state-action spaces. Additionally, performing safe control in the face of uncertainty is one of the biggest impediments to deploying robots in the real world, an impediment that RL methods have not yet tackled. In contrast, a distributional approach can allow robots to learn an RL policy that appropriately quantifies risks for the task of interest.
However, given the brittle nature of deep RL algorithms and their often
counter-intuitive behaviour
In this paper, we aim to address this need and perform a thorough
analysis of distributional Q-learning algorithms in simulated and real
vision-based robotic manipulation tasks. To this end, we propose a
distributional enhancement of QT-Opt
In particular, we introduce two versions of Q2-Opt, based on Quantile Regression DQN (QR-DQN)
Related Work
Deep learning has shown to be a useful tool for learning visuomotor
policies that operate directly on raw images. Examples include various
manipulation tasks, where related approaches use either supervised
learning to predict the probability of a successful
grasp
Distributional Q-learning algorithms have been so far a separate line of
research, mainly evaluated on game environments. These algorithms
replace the expected return of an action with a distribution over the
returns and mainly vary by the way they parametrize this distribution.
Bellemare et al.
Closest to our work is D4PG
Background
As previously stated, we build our method on top of
QT-Opt
In this paper, we consider a standard Markov Decision Process
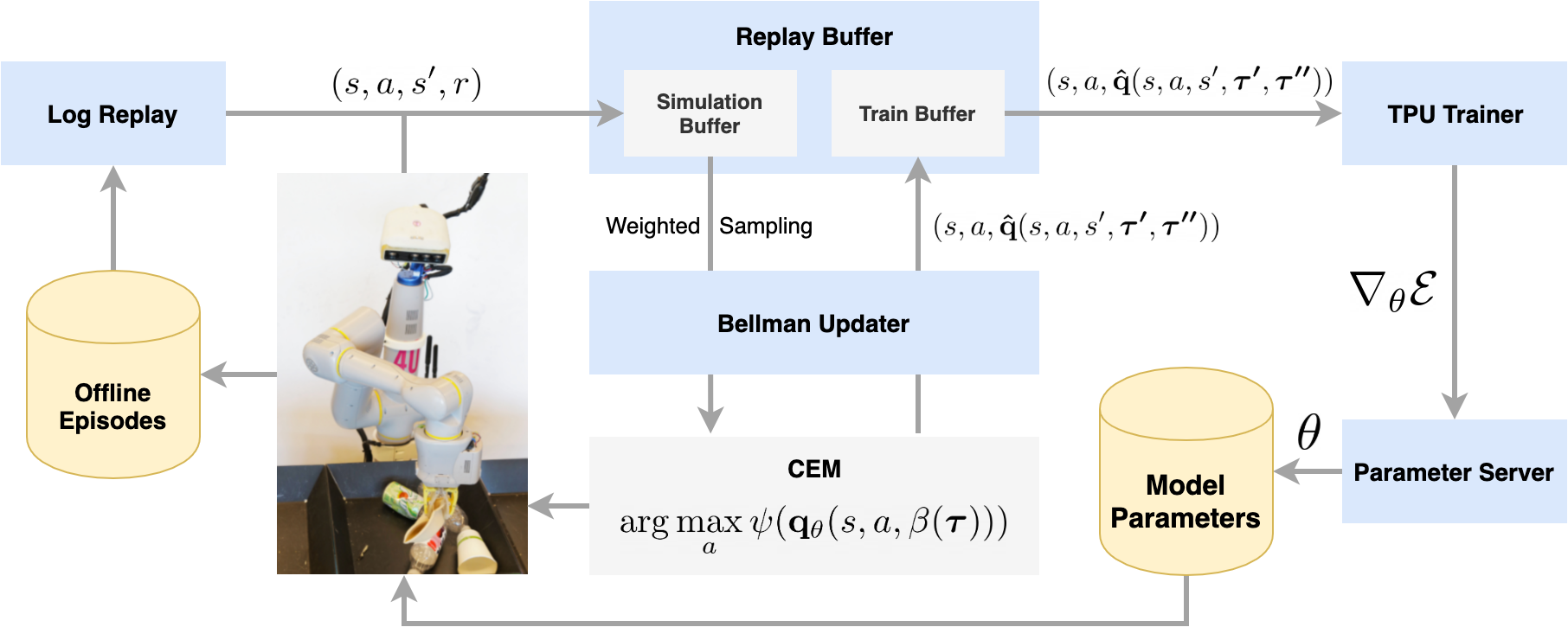
In order to train the Q-function, a separate process called the "Bellman
Updater" samples transition tuples containing the state
, action , reward , and next state from a replay buffer
and generates Bellman target values according to a clipped Double
Q-learning rule
where , and and are the parameters of two delayed target networks. These target values are pushed to another replay buffer , and a separate training process optimizes the Q-function against a training objective:
where is a divergence metric.
In particular, the cross-entropy loss is chosen for , and the output of the network is passed through a sigmoid activation to ensure that the predicted Q-values are inside the unit interval.
Quantile QT-Opt (Q2-Opt)
In Q2-Opt (Figure 1) the value function no longer predicts a scalar value, but rather a vector that predicts the quantile function output for a vector of input probabilities , with and . Thus the -th element of approximates , where is the CDF of the value distribution belonging to the state action pair . In practice, this means that the neural network has a multi-headed output. However, unlike QT-Opt where CEM optimizes directly over the Q-values, in Quantile QT-Opt, CEM maximizes a scoring function that maps the vector to a score :
Similarly, the target values produced by the “Bellman updater” are vectorized using a generalization of the clipped Double Q-learning rule from QT-Opt:
where \vone is a vector of ones, and, as before, and are the parameters of two delayed target networks. Even though this update rule has not been considered so far in the distributional RL literature, we find it effective in reducing the overestimation in the predictions.
In the following sections, we present two versions of Q2-Opt based on two recently introduced distributional algorithms: QR-DQN and IQN. The main differences between them arise from the inputs , and that are used. To avoid overloading our notation, from now on we omit the parameter subscript in and replace it with an index into these vectors .
Quantile Regression QT-Opt (Q2R-Opt)
In Quantile Regression QT-Opt (Q2R-Opt), the vectors in and are fixed. They all contain quantile midpoints of the value distribution. Concretely, is assigned the fixed quantile target with . The scoring function takes the mean of this vector, reducing the quantile midpoints to the expected value of the distribution. Because are always fixed we consider them implicit and omit adding them as an argument to and for Q2R-Opt.
The quantile heads are optimized by minimizing the Huber
for all the pairwise TD-errors:
Thus, the network is trained to minimize the loss function:
We set , the threshold between the quadratic and linear regime of the loss, to across all of our experiments.
Quantile Function QT-Opt (Q2F-Opt)
In Q2F-Opt, the neural network itself approximates the quantile function of the value distribution, and therefore it can predict the inverse CDF for any . Since are no longer fixed, we explicitly include them in the arguments of and . Thus, the TD-errors take the form:
where , and are sampled from independent uniform distributions. Using different input probability vectors also decreases the correlation between the networks. Note that now the length of the prediction and target vectors are determined by the lengths of and . The model is optimized using the same loss function as Q2R-Opt.
Risk-Sensitive Policies
The additional information provided by a value distribution compared to the (scalar) expected return gives birth to a broader class of policies that go beyond optimizing for the expected value of the actions. Concretely, the expectation can be replaced with any risk metric, that is any function that maps the random return to a scalar quantifying the risk. In Q2-Opt, this role is played by the function that acts as a risk-metric. Thus the agent can handle the intrinsic uncertainty of the task in different ways depending on the specific form of . It is important to specify that this uncertainty is generated by the environment dynamics () and the (non-stationary) policy collecting the real robot rollouts and that it is not a parametric uncertainty.
We distinguish two methods to construct risk-sensitive policies for Q2R-Opt and Q2F-Opt, each specific to one of the methods. In Q2R-Opt, risk-averse and risk-seeking policies can be obtained by changing the function when selecting actions. Rather than computing the mean of the target quantiles, can be defined as a weighted average over the quantiles . This sum produces a policy that is in between a worst-case and best-case action selector and, for most purposes, it would be preferable in practice over the two extremes. For instance, a robot that would consider only the worst-case scenario would most likely terminate immediately since this strategy, even though it is not useful, does not incur any penalty. Behaviours like this have been encountered in our evaluation of very conservative policies.
In contrast, Q2F-Opt provides a more elegant way of learning risk-sensitive control policies by using risk-distortion metrics
The key idea is to use a policy:
where is an element-wise function that distorts the uniform distribution that is effectively sampled from, and computes the mean of the vector as usual. Functions that are concave induce risk-averse policies, while convex function induce risk-seeking policies.

In our experiments, we consider the same risk distortion metrics used by
Dabney et al.
Due to the relationships between Q2F-Opt and the literature of risk distortion measures, we focus our risk-sensitivity experiments on the metrics mentioned above and leave the possibility of trying different functions in Q2R-Opt for future work.
Model Architecture
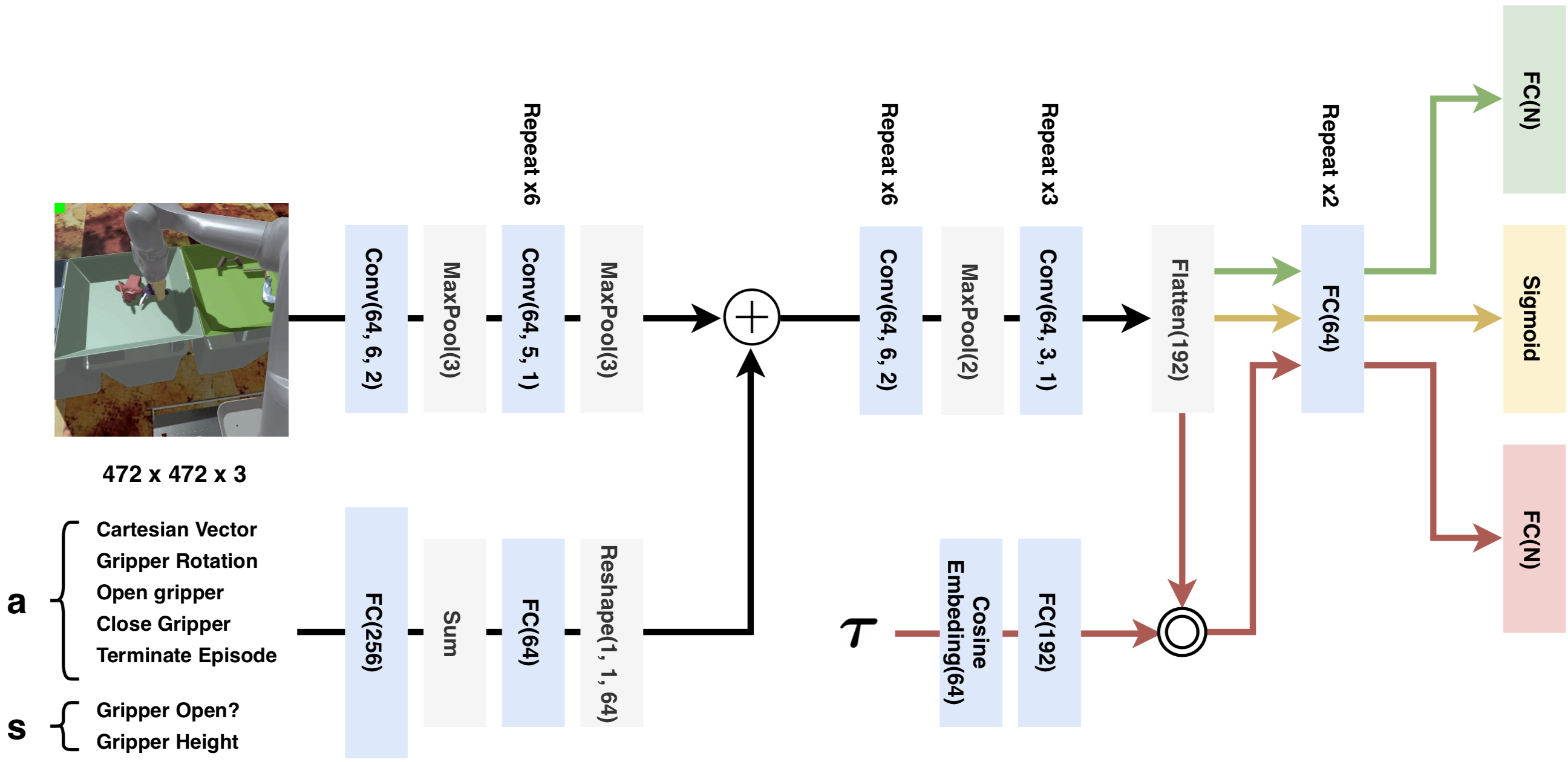
To maintain our comparisons with QT-Opt, we use very similar
architectures for Q2R-Opt and Q2F-Opt. For Q2R-Opt, we modify the output
layer of the standard QT-Opt architecture to be a vector of size
, rather than a scalar. For Q2F-Opt, we take a similar approach
to Dabney et al.
We then perform the Hadamard product between this embedding and the convolutional features.
Another difference in Q2F-Opt is that we replace batch normalization
Results
In this section, we present our results on simulated and real environments. In simulation, we perform both online and offline experiments, while for the real world, the training is exclusively offline. We begin by describing our evaluation method.
Experimental Setup
We consider the problem of vision-based robotic grasping for our evaluations. In our grasping setup, the robot arm is placed at a fixed distance from a bin containing a variety of objects and tasked with grasping any object. The MDP specifying our robotic manipulation task provides a simple binary reward to the agent at the end of the episode: for a failed grasp, and for a successful grasp. To encourage the robot to grasp objects as fast as possible, we use a time step penalty of and a discount factor . The state is represented by a RGB image; the actions are a mixture of continuous 4-DOF tool displacements in , , with azimuthal rotation , and discrete actions to open and close the gripper, as well as to terminate the episode.
In simulation, we grasp from a bin containing 8 to 12 randomly generated
procedural objects (Figure 2). For the first global training
steps, we use a procedural exploration policy. The scripted policy is
lowering the end effector at a random position at the level of the bin
and attempts to grasp. After steps, we switch to an
-greedy policy with . We train the network
from scratch (no pretraining) using Adam
In the real world, we train our model offline from a TiB dataset of real-world experiences collected over five months, containing episodes of up to time steps each. Out of these, were generated by noise-free trained QT-Opt policies, by an -greedy strategy using trained QT-Opt policies and by an -greedy strategy based on a scripted policy. For evaluation, we attempt 6 consecutive grasps from a bin containing 6 objects without replacement, repeated across 5 rounds. Figures 2 and 3 include our workspace setup. We perform this experiment in parallel on 7 robots, resulting in a total of grasp attempts. All the robots use a similar object setup consisting of two plastic bottles, one metal can, one paper bowl, one paper cup, and one paper cup sleeve. In the results section, we report the success rate over the attempts.
Our evaluation methodology is different from that of Kalashnikov et al.
Simulation Experiments
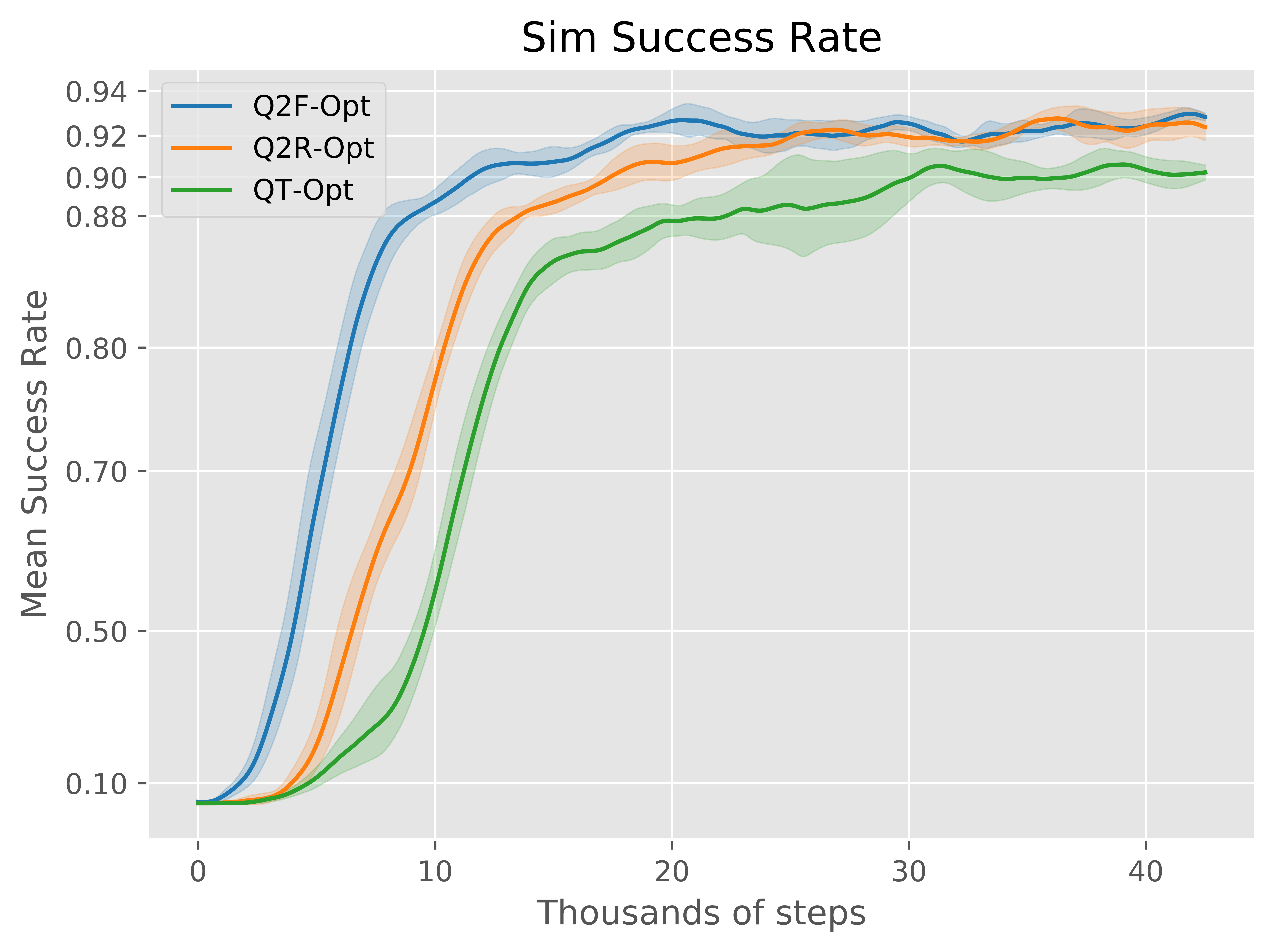
We begin by evaluating Q2-Opt against QT-Opt in simulation. Figure. Figure 3 shows the mean success rate as a function of the global training step together with the standard deviation across five runs for QT-Opt, Q2R-Opt and Q2F-Opt. Because Q2-Opt and QT-Opt are distributed systems, the global training step does not directly match the number of environment episodes used by the models during training. Therefore, to understand the sample efficiency of the algorithm, we also include in Figure 4 the success rate as a function of the total number of environment episodes added to the buffer.
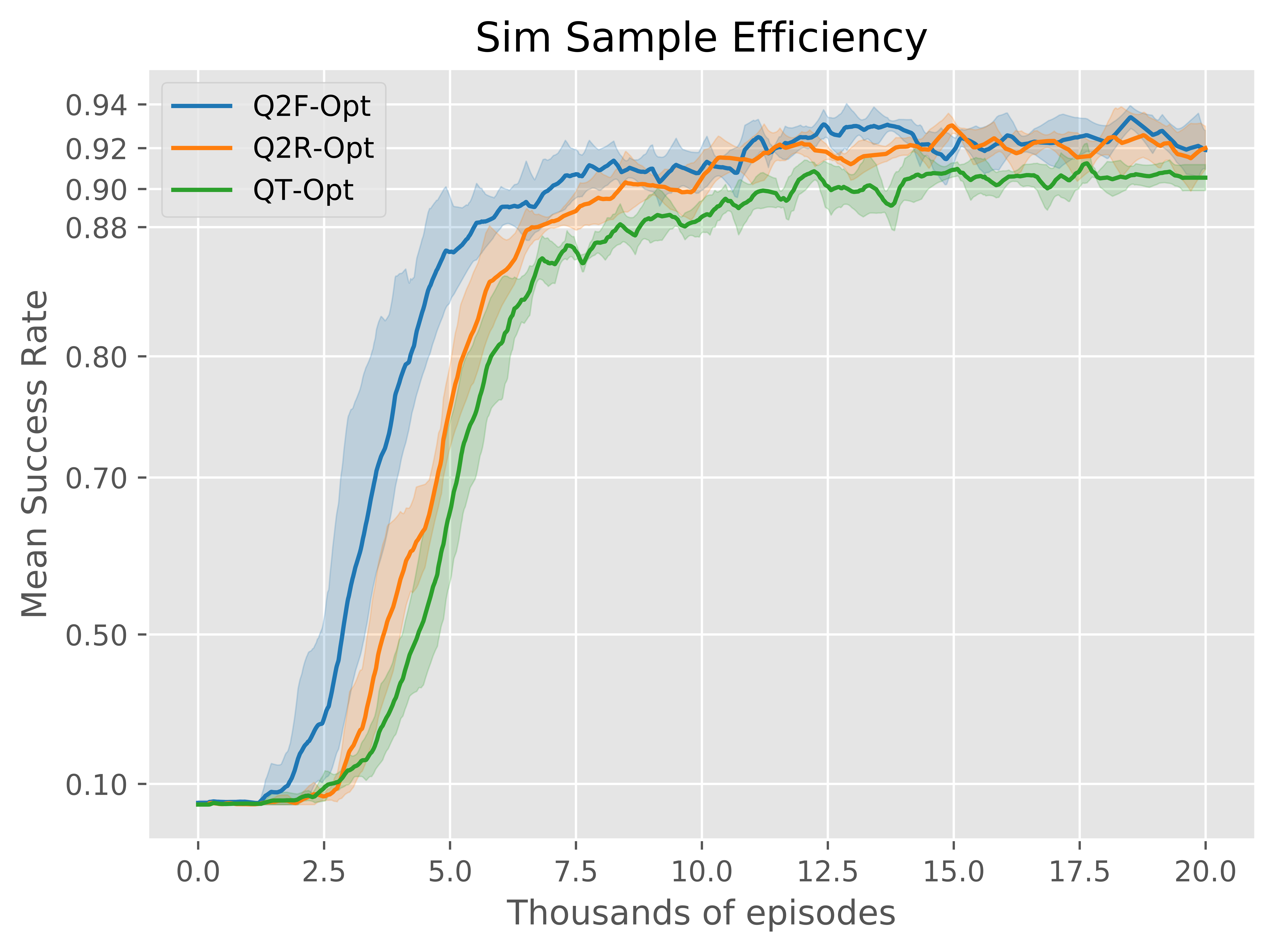
The distributional methods achieve higher success rates while also being more sample efficient than QT-Opt. While Q2F-Opt performs best, Q2R-Opt exhibits an intermediary performance and, despite being less sample efficient than Q2F-Opt, it still learns significantly faster than our baseline.
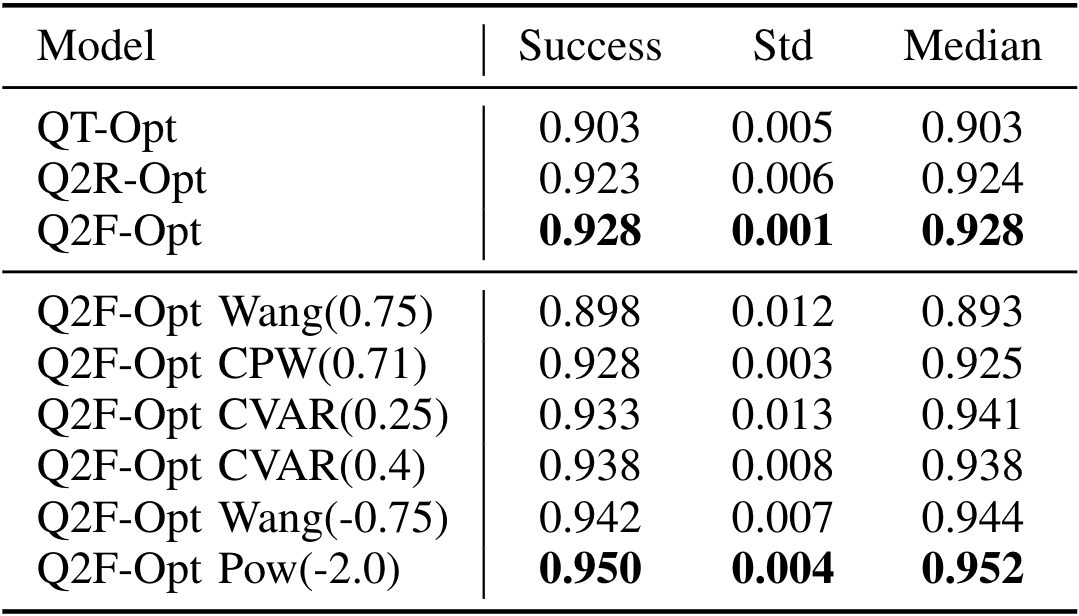
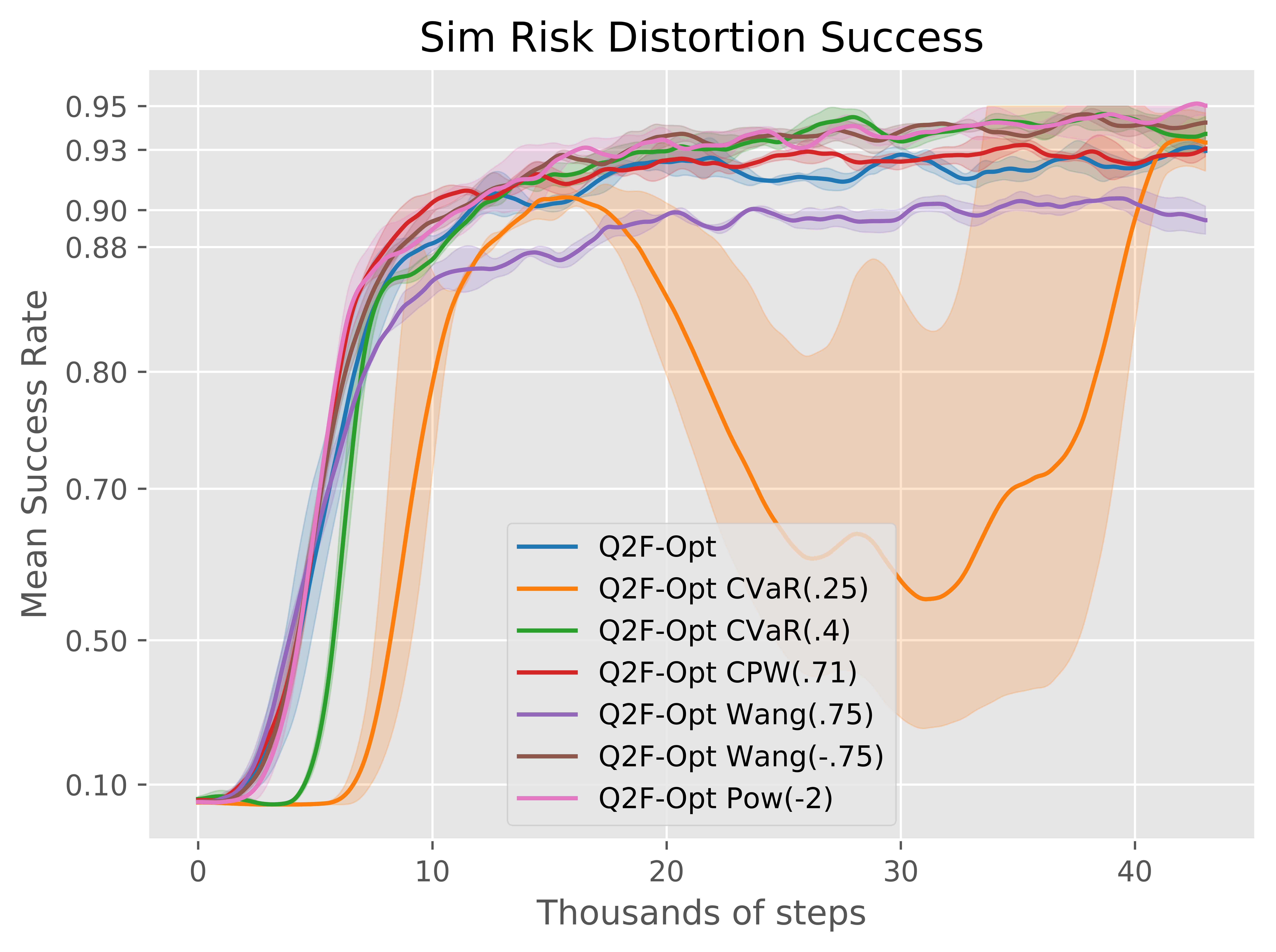
We extend these simulation experiments with a series of risk distortion measures equipped with different parameters. Figure 5 shows the success rate for various measures used in Q2F-Opt. We notice that risk-averse policies (Wang, Pow, CVaR) are generally more stable in the late stages of training and achieve a higher success rate. Pow remarkably achieves 95% grasp success rate. However, being too conservative can also be problematic. Particularly, the CVaR policy becomes more vulnerable to the locally optimal behaviour of stopping immediately (which does not induce any reward penalty). This makes its performance fluctuate throughout training, even though it ultimately obtains a good final success rate. Table 2 gives the complete final success rate statistics.
Real-World Experiments
The chaotic physical interactions specific to real-world environments and the diversity of policies used to gather the experiences make the real environment an ideal setting for distributional RL. Furthermore, this experiment is also of practical importance for robotics since any increase in grasp success rate from offline data reduces the amount of costly online training that has to be performed to obtain a good policy.
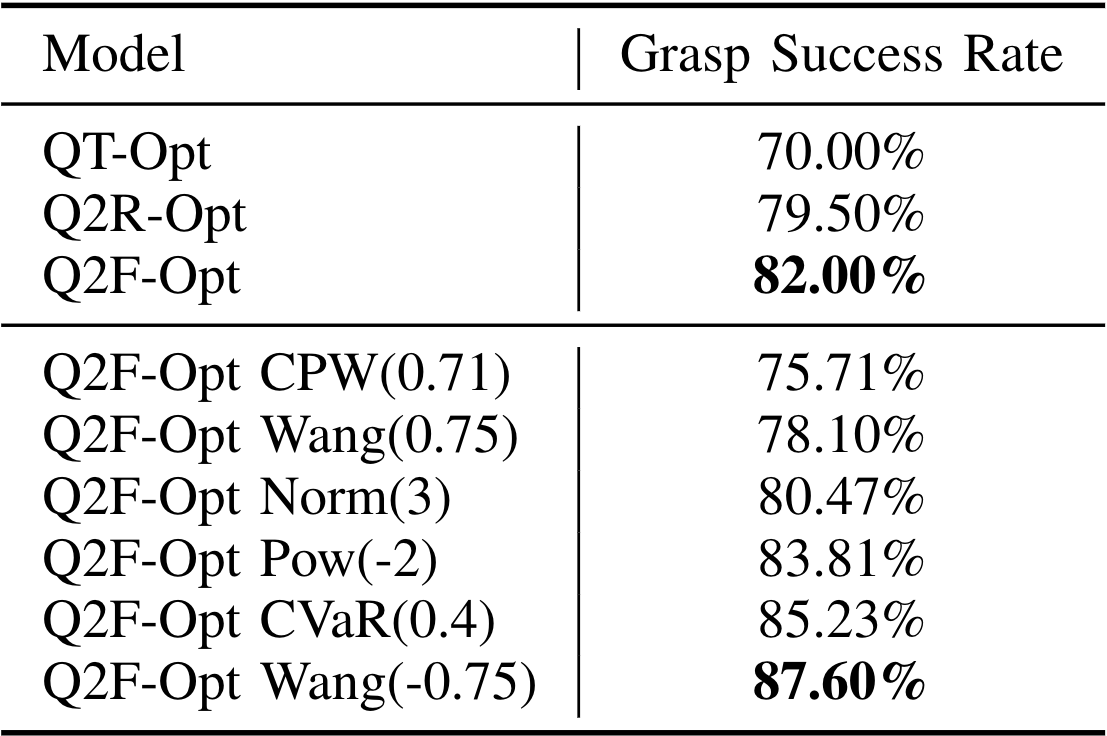
We report in Table 3 the grasp success rate statistics for all the considered models. We find that the best risk-averse version of Q2-Opt achieves an impressive 17.6% higher success rate than QT-Opt. While the real evaluation closely matches the model hierarchy observed in sim, the success rate differences between the models are much more significant.
Besides the improvement in performance, we notice that the distortion measures of Q2F-Opt have a significant qualitative impact, even though the training is performed from the same data. Risk-averse policies tend to readjust the gripper in positions that are more favourable or move objects around to make grasping easier. CVaR(0.4), the most conservative metric we tested in the real world, presented a particularly interesting behaviour of intentionally dropping poorly grasped objects to attempt a better re-grasp.
The CVaR policy mainly used this technique when attempting to grasp objects from the corners of the bin to move them in a central position. However, a downside of risk-averse policies that we noticed is that, for the difficult-to-grasp paper cup sleeves, the agent often kept searching for an ideal position without actually attempting to grasp. We believe this is an interesting example of the trade-offs between being conservative and risk-seeking.
The only tested risk-seeking policy, using Wang(0.75), made many high-force contacts with the bin and objects, which often resulted in broken gripper fingers and objects being thrown out of the bin.
These qualitative differences in behaviour that value distributions cause can provide a way to achieve safe robot control. An interesting metric we considered to quantify these behaviours is the number of broken gripper fingers throughout the entire evaluation process presented above. Occasionally, the gripper fingers break in high-force contacts with the objects or the bin. Figure 6 plots these numbers for each policy. Even though we do not have a statistically significant number of samples, we believe this figure is a good indicator that risk-averse policies implicitly achieve safer control.
Batch RL and Exploitation
Recently, Agarwal et al.
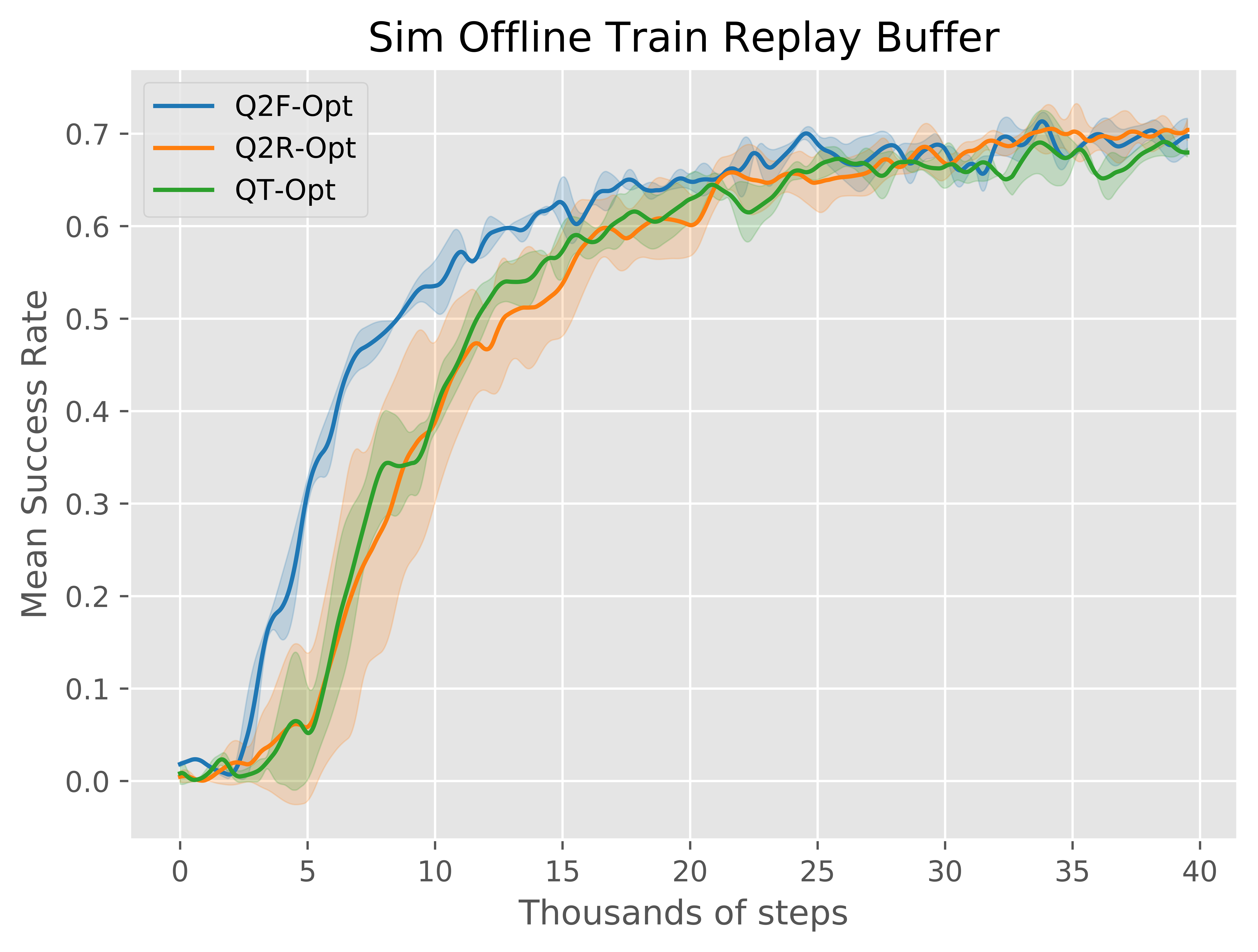
We note that despite the minor success rate improvements brought by
Q2R-Opt and Q2F-Opt, the two models are not even capable of achieving
the final success rate of the policy trained from the same data. We
hypothesize this is due to the out-of-distribution action
problem
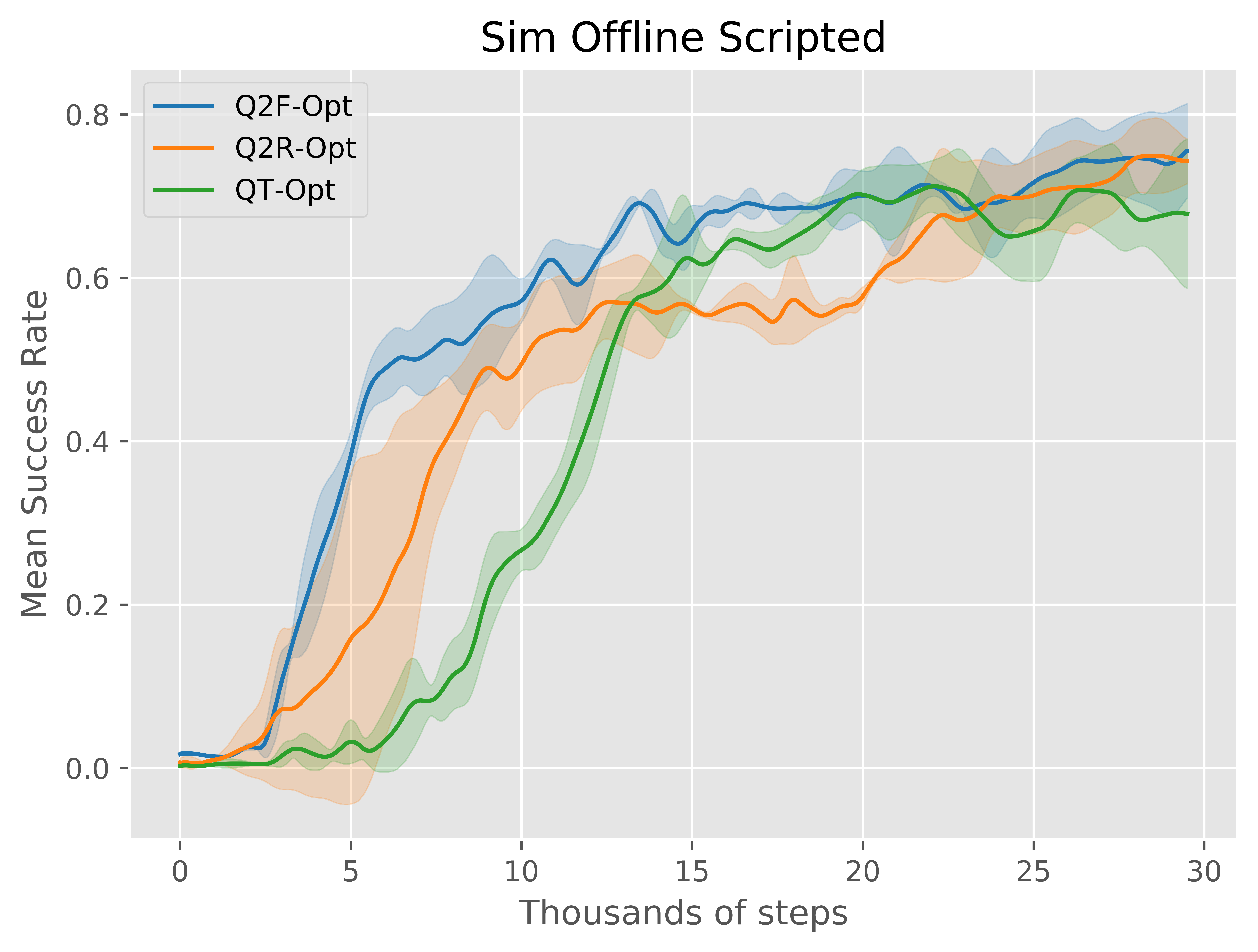
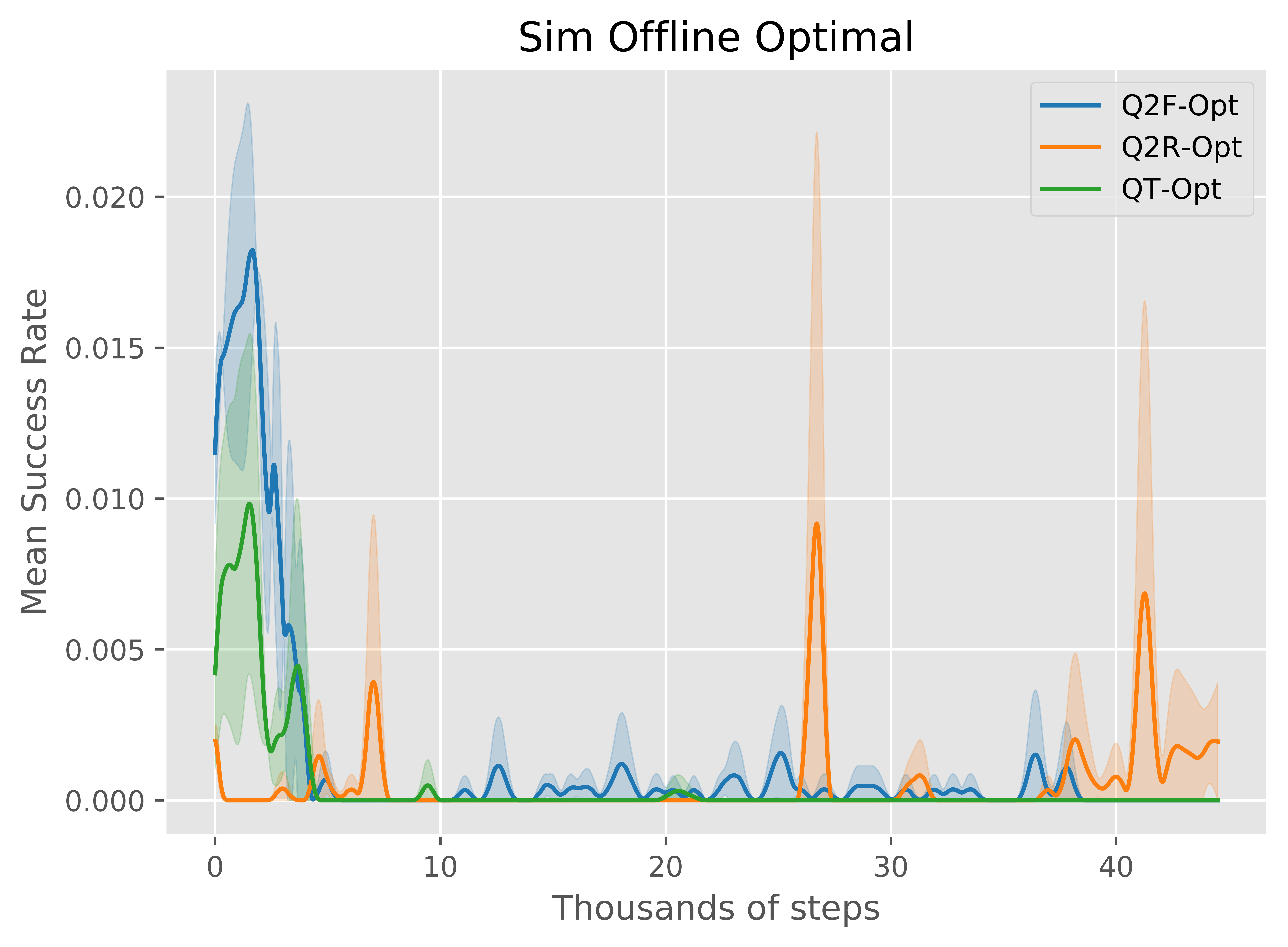
We investigated this further on two other datasets: one collected by a scripted stochastic exploration policy with success rate and another produced by an almost optimal policy with grasp success rate. Figures 7b and 7c plot the results for these two datasets. Surprisingly, the models achieve a higher success rate on the scripted exploration dataset than on the dataset collected during training. On the dataset generated by the almost optimal policy, none of the methods manages to obtain a reasonable success rate. These results, taken together with our real-world experiments, suggest that offline datasets must contain a diverse set of experiences to learn effectively in a batch RL setting.
Conclusion
In this work, we have examined the impact that value distributions have
on practical robotic tasks. Our proposed methods, collectively called
Q2-Opt, achieved state-of-the-art success rates on simulated and real
vision-based robotic grasping tasks, while also being significantly more
sample efficient than the non-distributional equivalent, QT-Opt.
Additionally, we have shown how safe reinforcement learning control can
be achieved through risk-sensitive policies and reported the rich set of
behaviours these policies produce in practice despite being trained from
the same data. As a final contribution, we evaluated the proposed
distributional methods in a batch RL setting similar to that of Agarwal
et al.
Acknowledgments
We would like to give special thanks to Ivonne Fajardo and Noah Brown for overseeing the robot operations. We would also like to extend our gratitude to Julian Ibarz for helpful comments.